GraphQL at Scale using Apollo, NodeJs and Angular

Nov 19, 2019 • 9 min read

GraphQL is the coolest thing I have seen in technology for quite a while. Usually, I looked at new technology and see what’s coming, and say that’s cool, but at the same time, I see that lots of things trying to solve the same problem. So I kind of not eager to jump into right away, I kind of wait and see what happens.
With GraphQL I’ll go deep in some of those features, but before that, there are few things I really find exciting about GraphQL.
GraphQL helps both sides of the technology, the front-end, and the backend.
How it helps front-end?
The GraphQL enables front-end developers to get into the code and build something, without worrying too much about HTTP requests or setting up the fetch, or even really don’t care about knowing how Asynchronous request works. You just install the Apollo Client and it happens. Which I think is really a big development on the front-end.
How it helps back-end?
There are lots of cool things on the back-end as well, the centralize data layer, centralize documentation especially at scale. I don’t know how big your company is but I am sure, the documentation is bad :)
Problems at scale
Dealing with a small scale and a small team is easy, but when you scale that size to hundreds of engineers and dozens of teams things become hard and slow. Before I jump into the GraphQL features and benefits, let’s talk about some of those problems.
Changes in multiple directions
In a big company with multiple teams owning their μ-service, with their own separate code base, the changes start to happen in multiple directions at once.
And because of these changes, somebody had to get on the slack channel and say Hey our app just broke and I think it’s because of this endpoint, does anybody know who works on that, so that I can ask what’s different because it’s definitely not documented.
Multiple μ-service for front-end
Front-end has to touch lots of end-points to get data, which means they are reaching to a lot of places, and if you are in a back-end team, and you need to make a breaking change. It’s really difficult to know which front-ends are using your stuff.
So most of the time the way we fix the breaking changes, are we just break it. And we wait for the front-end team to tell us that something broke.
Multiple endpoints for related data
Suppose we have a REST API which gets us all the books from one endpoint, let’s say that endpoint is api/books but the problem is it only returns the information about the book, not related information such as author, reviewers, reviews and etc.
There are several ways we can solve this problem
- Send related information with the same API, which means every request on
api/bookswill return books with all its related information. - Ask the client to make additional calls to fetch related information.
- Create new endpoint which returns the books with their authors such as
api/books-with-authorsand for reviews and authorapi/books-with-reviews-and-authorand so on.
Inconsistent documentation
Internal documentation and architecture are inconsistent, everybody tries to put swagger API documentation for their APIs.
And in most cases, those swagger docs are 80% complete and 99% out of date.
API versioning
API versioning is another major challenge. We face every time we need to make breaking changes. We need to make sure that the clients using the current version of the APIs can also run smoothly.
So we end up maintaining multiple versions of the same APIs.
How GraphQL helps?
All the problems which I have mentioned can be solved in many ways which require multiple tools and techniques to explore and integrate.
GraphQL in the other hand solves many of these problems in a very efficient and simple manner.
It helps centralize the changes
With GraphQL your changes get centralized, if backend teams make a breaking change, they only need to tell the GraphQL Layer and every client will know about it automatically.
GraphQL can deprecate, add notes and give clients to find the updated documentation so everyone is aware before something breaks or will break in the future. Which is not something easy to do with other solutions.
One single endpoint for front-end
With GraphQL the data access has to go through one single endpoint. This means front-end developers should not be worried about the multiple HTTP URLs.
I don’t really want to get deep into it but making one HTTP call is always easier than making 10.
Single endpoint for related data
With GraphQL client can query the information and data they need in a recursive format.
So if the user needs all the books with its author, they don't have to wait until backend can provide that endpoint, they also don’t need to make more calls to fetch the related information, they simply query the data they want
# Schema on server
type Author {
name: String
}
type Review {
comment: String
rating: Float
}
type Book {
title: String
author: Author
reviews: [Review]
}
# type Query
type Query {
books: [Book]
}
# query on client
query {
books {
title
author {
name
}
reviews {
comment
rating
}
}
}Consistent documentation
Documentation in GraphQL is automatic, centralize and consistent. You cannot release a GraphQL schema without it getting documented at least in a normal fashion.
GraphQL also comes with a UI tool called GraphiQL. So even if you don’t write docs, people can go there and check out the queries, mutations, and types provided by the API
They also can run these queries and mutation there to see it in action.
Single API version
GraphQL makes API changes easy, we simply can modify the schema and put directives and alias to support the older integration.
If a client trying to access any property which is deprecated, we still can get them the data and also show them warnings about these depreciations.
Which means we have one single API version to maintain.
GraphQL elements
GraphQL have some of its own terms and conventions, there are a few of them are important
Schema and Types
A GraphQL schema is at the center of any GraphQL server. The schema describes the functionality available to the clients, in the form of Type, Query, and Mutation.
# type Book
type Book {
title: String
author: Author
}
# type Author
type Author {
name: String
books: [Book]
}The core building block within a schema is the Type, it helps to provide a wide range of functionality within a schema, including the ability to create relationships between types, which you can see in the code snippet, the book and author are related to each other.
# Query books
type Query {
books: [Book]
}
# Mutaion saveBook
type Mutation {
saveBook(book: BookInput): Book
}It defines which queries can get you what type of data and which mutation allows you to send what type of data.
Everything in GraphQL is simply a type but when we combine these types together we get a Schema.
Directive and Context
A directive is an identifier preceded by a @ character. It also can have a list of named arguments which we can define at the time schema design to reuse these directives on various use cases.
directive @deprecated(
reason: String = "No longer supported."
) on FIELD_DEFINITION
type UserType {
fullName: String @deprecated(reason: "Use name.")
}In this example, we have defined a deprecated directive, which accepts a reason of type string and can be applied to field-definitions.
Which we have simply used in UserType to tell the clients to use name property instead of fullName.
The context in GraphQL works as middleware and we can use it to define the functionality of a directive, manipulate the headers to add authentication token or implement access rules on properties and types.
# Define alias directive in schema
directive @alias(
resolveTo: String
) on FIELD_DEFINITION
# Use the alias directive in the field
type UserType {
fullName: String @alias(resolveTo: 'name')
}
# Resolve the field value
export default class AliasDirective extends SchemaDirectiveVisitor {
visitFieldDefinition(field: any){
# Add the resolveTo value to the field as alias
field.alias = this.args.resolveTo;
}
visitObject(type: any) {
const fields = type.getFields();
Object.keys(fields).forEach(_name => {
const field = fields[_name];
if(field.alias) {
field.resolve = fields[field.alias].reolve;
# or you can simply throw and error here :)
}
});
}
}In the above example, we have defined an alias directive and resolved it with the mentioned field using context.
Resolver and Data Source
Resolvers are also the key to GraphQL, each resolver represents a single field and nd they are asynchronous. Which means they can fetch the data from any source you may have.
# Query books
type Query {
books: [Book]
}
# Mutaion saveBook
type Mutation {
saveBook(book: BookInput): Book
}
# resolvers
resolvers = {
Query: {
books: fetch('api/books')
},
Mutation: {
saveBook: BookModel.save
}
}We organize our resolves as one to one mapping to our queries and mutations, you can see in the above example.
The Data Source in the GraphQL is the classes that allow us to fetch and save data from a particular service.
It can be a REST service you can see in the Query example where I am fetching all the books directly from api/books REST API.
Or it can be a database model from MySQL, MongoDB and etc, which you can see in the Mutation example where I am using save method of BookModel to save the data.
Why Apollo?
GraphQL seems simple and easy. But when it comes to implementation its little complex. There are so many things to consider which requires time and a deep understanding of GraphQL.
Apollo in the other hand makes everything quick and easy on the server using Apollo Server and on the client using Apollo Client.
A complete GraphQL ecosystem
Apollo is an implementation of a complete GraphQL ecosystem, which provides everything you need to get started with GraphQL in no time.
The Apollo ecosystem offers a complete GraphQL solution for small, medium and enterprise companies. They support a wide range of technology stacks, frameworks, and libraries, making it's easy and quick to get started with GraphQL.
Lots and lots of features
Apollo is feature-rich, it comes with lots and lots of features, which pull all the GraphQL complexity out the application and handle the interaction between client and server smoothly.
For instance, Apollo client caches request to ensure that the calls are made only once if the result is already in the cache, which provides a performance boost for the application by saving valuable network traffic.
Apollo Client normalizes the data, so nested data from a GraphQL query can store in a normalized form in the cache, it uses a unique identifier to identify which data belongs to what.
Beyond the caching and normalization, Apollo Client comes with many other features, Error Handling, Error management, Pagination, Data prefetching, Optimistic user interface, documentation, etc.
Robust and concise documentation
While Apollo continues to evolve, the team and community behind it keep the documentation up to date, and they have plenty of insight about how to build applications.
In fact, they cover so many areas it can be overwhelming for beginners.
Their documentation does not only contains the features and services offered by Apollo but a complete guide, to understand GraphQL and how it works behind the scene.
GraphQL Schema Design at Scale
Till now we have a good understanding of GraphQL, what sort of problems it helps to solve, how Apollo makes our life as a developer easy to get started with GraphQL
So let’s jump right into the GraphQL schema, and understand how a schema can be designed at a scale.
A typical GraphQL Schema contains thee major parts
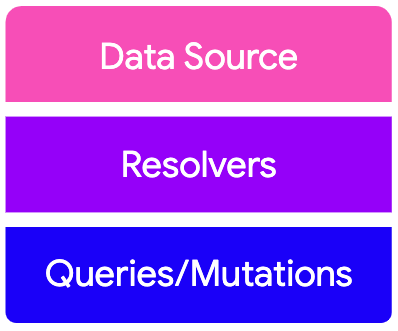 A Typcial GraphQL Schema
A Typcial GraphQL Schema
- Query, Mutations, and Types
- Resolvers, which are the interfaces, by which we fetch or save data requested or sent by the client.
- Data Source, which can be a REST service, Database model, data loader and etc.
This is fine if you have only one schema to deal with, but when it comes to scale and multiple μ-services managed by multiple teams, a single schema does not work, teams want more control, from where their data is provided and how it is being sent to the client.
To solve this problem we need to have a distributed schema architecture, which means every team can have their own schema so that they can control the data, and we need something to stitch these schemas together for the client to have single end-point and centralized documentation.
Luckily, GraphQL has a feature called schema stitching, which is designed for these use cases, which is also very simple to integrate.
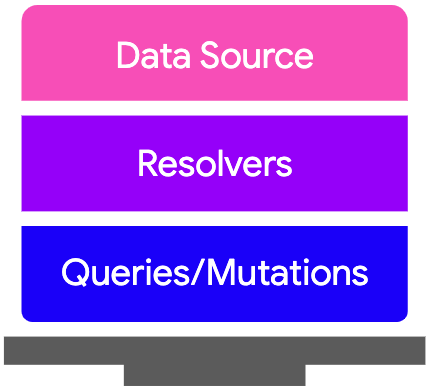 GraphQL schema with export
GraphQL schema with export
All you have to do it add a connector to each schema, which exports the individual schema from various teams and can be combined for the client.
So we take these schemas from various teams along with their connector, import them into the Apollo server, which gets us the one single end-point to interact with all the available queries, mutations, and types.
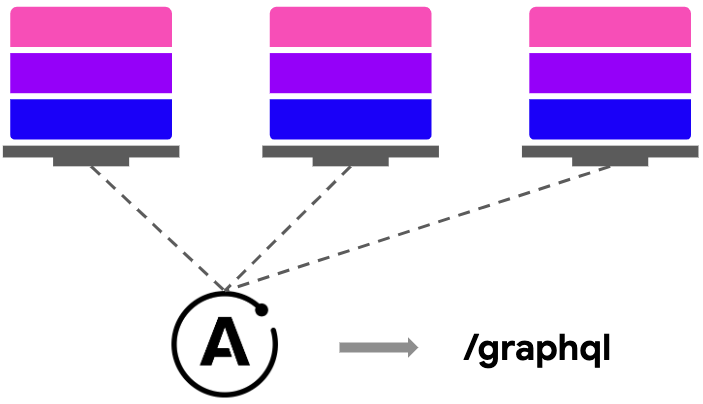 Combining schemas together
Combining schemas together
There is one thing to note here, that we must have unique names for their types, queries, and mutations just to avoid any overlap.
FAQs
People seem a little confused when it comes to GraphQL and REST, let me be clear on this that REST and GraphQL are not comparable with each other, they solve very distinct problems.
Find a few of the most asked questions and concerns about GraphQL
It always returns a response code of 200 regardless of success or error which would make error handling difficult and additional complexity in monitoring
GraphQL is very different from the REST so HTTP status codes are redundant. As error handling is concern GraphQL provides Network and GraphQL type of errors in their interfaces which we set up while creating the GraphQL links and adapters.
Issues in URI based caching
GraphQL provides query caching which can be set up during the link/adopter creation
Native HTTP caching would not help because there is a single endpoint which means building your own cache support or using some third-party libs
The caching in GraphQL is more robust compared to HTTP caching, follow the link to know more https://graphql.org/learn/caching/
Difficulty in exposing APIs to external parties as not everyone would use GraphQL
This can be solved simply by adding routes for specific data which internally uses GraphQL.
File uploads were difficult; there was no direct support in mutation for it
Apollo 2.0 has added Upload scaler type which lets you upload files. https://blog.apollographql.com/file-uploads-with-apollo-server-2-0-5db2f3f60675
Rate limiting would be difficult because a user can fire multiple queries in a single request
By using context APIs and directives we can implement any logic for rate limiting, authorization and etc.
Boilerplate code even for very simple APIs
Building APIs which can scale and provide features required additional code in every language or framework.
Of course, a learning curve.
I agree there will be some learning curve moving from REST to GraphQL but the features and functionality we get can compensate for that.
Ashok Vishwakarma
Google Develover Expert — WebTechnologies and Angular | Principal Architect at Naukri.com | Entrepreneur | TechEnthusiast | Speaker